
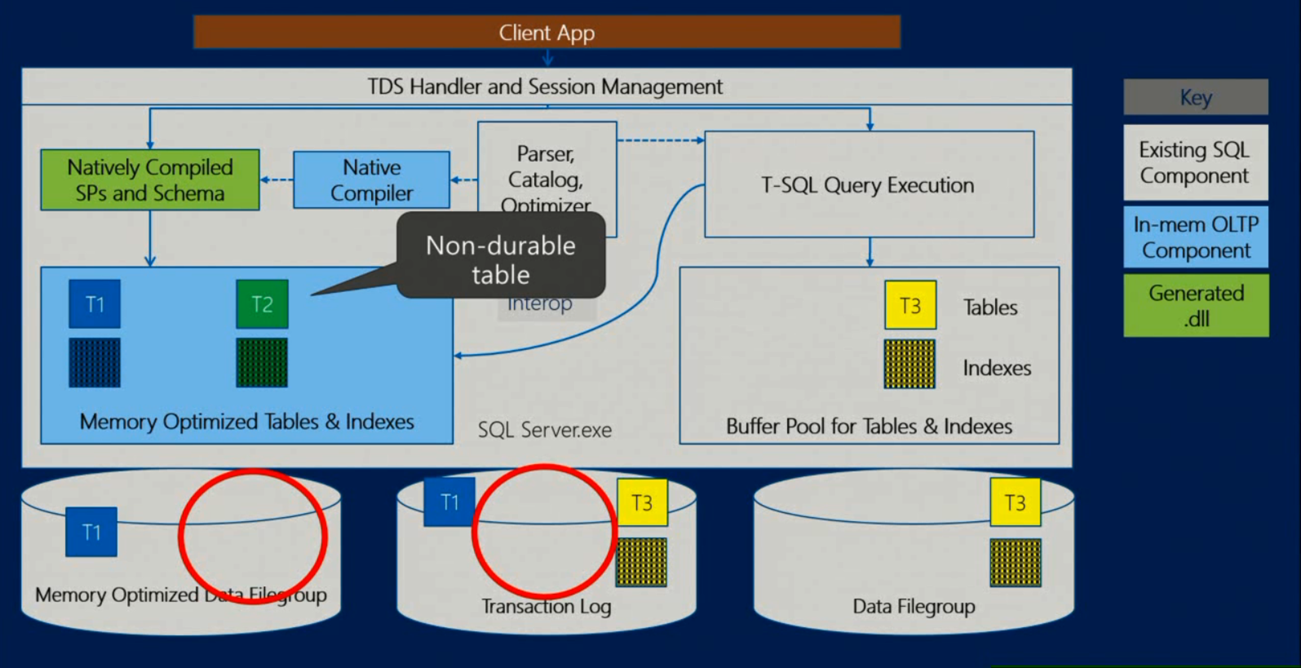
Veri yönetimi trendi, giderek artan ve hızla talep edilmek istenen yoğun veri ihtiyacı gereği diskten memory tarafına doğru kayıyor. Microsoft da SQL Server 2014 ile birlikte bu alana yatırımlarını yaptı ve In-Memory teknolojisini müşterilerine duyurdu.
CTP1 versiyonuna nazaran biraz daha geliştirilen bu teknoloji iki ayrı başlıkta incelenebilir durumda. Bu başlıklardan birisi OLTP modeldeki veri tabanlarının INSERT, UPDATE, DELETE performanslarını arttırmak için kullanılabilecek bir çözüm olan In-Memory OLTP dir. Diğer başlık ise Veri ambarı gibi genelde de-normalize yapıda tutulan veri tabanlarının SELECTperformansını arttıracak bir çözüm olan In-Memory DW dir. Bu yazımızda In-Memory OLTP kısmına odaklanıyor olacağız.
Hekaton adı ile anılan yeni bir engine dizayn edildi ve var olan database engine bileşenlerine entegre hale getirildi. Yani SQL Server 2014 kurulumunu yaptığınızda artık kolayca In-Memory OLTP teknolojisinden de faydalanabileceksiniz demektir.
Bu entegrasyon sayesinde veri tabanı üzerindeki çalışma alışkanlıklarınızı çok fazla değiştirmenize gerek kalmayacak. Tabi ki bu yeni teknolojiyi mevcut sistem ile birlikte kullanmaya başladığımızda bazı kısıtlarla karşılaşmamamız kaçınılmaz olacaktır. Bu kısıtlar tamamen yeni teknolojinin doğasından kaynaklanmaktadır.
In-Memory bileşenleri arka planda C tabanlı dll’ler ve FileStream özelliğini kullandığı için bunlarla çakışan hizmetlerden faydalanamayacaksınız demektir. Örneğin High Availability çözümlerinden AlwaysOn’u kurabilirlen zaten FileStream replikasyonu desteği olmayan Mirroring ve Replication(kısıtlı) kurulamayacaktır.
Aslında hemen hemen her şey C tabanlı çalışmanın getirilerine bağlı. Çünkü istenen talepler anında makine koduna çevriliyor ve işlemci tarafından işlenebiliyor.
Ayrıca veriler diskte veya buffer pool da değil direk memoryde tutuluyor. Dolayısıyla disk blockları üzerinde ve page mantığında çalışmanın dezavantajlarından kurtulmuş olunuyor. Aslına bakarsanız memorynin yetersiz olduğu durumlarda bu yöntemle çalışmak da başka bir dezavantaj oluyor.
Transaction yönetimini incelediğimizde ise şu özelliklerle karşılaşıyoruz:
- Tüm transactionlarda SNAPSHOT tabanlı isolation seviyeleri kullanılmakta. Bu sayede verinin birden fazla versiyonu üzerinde çalışabilmekte(Multi-Version). Snapshot tabanlı bu çalışma sırasında klasik Snapshot seviyesinden farklı olarak TempDBkullanılmıyor.
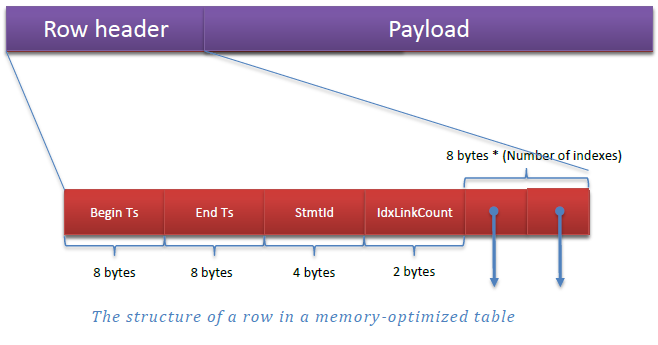
- Her satır versiyonu TIMESTAMP’ler yardımıyla değişiklikler için zaman aralıkları bilgisi tutuyor. Transactionlar doğru versiyonu seçmek ve validasyonu sağlamak için Begin Timestamp bilgisini kullanıyor.
- Bir satırda Row Header kısmında Begin Timestamp(Begin Ts), End Timstampt(End Ts) bilgilerinin yanı sıra satırı create eden ifadenin statement Id(SmtId) si ve tanımlı index pointerları için tutulan IdxLinkCount bilgisi yer almakta. Row Header’dan geriye kalan kısımda ise satırda tuttuğumuz veriler bulunmaktadır.
Verinin tutarlılığını sağlamak için çalışan lock ve latch mevcut değil (Optimistic). Dolayısıyla blocking gibi deadlock gibi durumlarla karşılaşılmıyor. Verinin tutarlılığı(tekrarlı okuma hayali okuma toleransları baz alınarak) transaction commit edilmeden hemen önce Validation evresinde kontrol ediliyor ve isolation seviyesine göre transactionın commit edilip edilmeyeceği belirleniyor.
Sadece In-Memory tablolarda kullanılabilecek Snapshot tabanlı 3 tane transaction isolation seviyesi mevcut. Bunlar klasik seviyelerden biraz farklı çalışıyor. Ancak tabi ki tüm transactionlar ACID kurallarını desteklemektedir. Sadece mantıksız bir sonuç oluştuğunda aldığınız hata karşısında işlemi tekrarlamanız gerekiyor. Bu durumla daha az karşılaşmak için mümkün olduğunca kısa süreli atomik transaction blokları oluşturmalısınız.
Isolation seviyelerine kısaca bir göz atalım:
Snapshot: Herhangi bir validasyon gerekli değil. Transactionlar verinin farklı bir versiyonu üzerinde çalışıyor ve ilk talep gönderen transactionın değişikliği onaylanır. Diğer transactionda ise erişim sırasında hata alınıyor.
Repeatable Reads: Snapshot seviyesindeki şartlar burada da sağlanır. Ek olarak transaction içerisinde okuma tutarlılığı garanti altına alınıyor. Transactiondan çıkmadan önce veride bir değişiklik olursa hata ile karşılaşıyor.
Serializable: Repeatable Reads seviyesindeki durum aynen geçerli. Ek olarak çalışılan aralığa farklı bir kaydın eklenmemesi veya kaydın silinmemesi (phantom) garanti altına alınıyor.
Transactionlar içerisinde In-Memory tablolar (Memory Optimized Table) ile disk tabanlı tabloları (Disk-Based Table) birlikte kullanabiliriz. Ancak tüm klasik isolation seviyeleri ile yukarıda belirttiğimiz isolation seviyeleri birlikte çalışamamaktadır.

Bu şekilde karma kullanımlarda Memory Optimized tablo erişimi için transaction seviyeleri WITH (SNAPSHOT) şeklinde belirtilmelidir. Aşağıdaki örnekte desteklenmeyen bir transaction seviyesi kullandığımızda nasıl bir hata aldığımızı görebiliriz.
In-Memory OLTP adı altında şu nesneleri oluşturabiliyoruz:
- Memory Optimized Data File Group
- Memory Optimized Table
o Hash Index
o Range Index
- Natively – Compiled Procedure
Bu nesneleri SQL Server kodları ile oluşturduğumuzda(çalıştırdığımızda) SQL Server tarafında tanımlanan metadata bilgisi kullanılarak C tabanlı dll’ler oluşur. Bu dll’leri ve C kodlarını aşağıdaki varsayılan yolda database Id leri ile oluşan klasörlerin içerisinde görebilirsiniz.
C:\Program Files\Microsoft SQL Server\MSSQL12.\MSSQL\DATA\xtp
Nesnelerin oluşan dll’lerini şu komut yardımıyla listelemek mümkün.
SELECT
name,
description
FROM sys.dm_os_loaded_modules
WHERE name LIKE '%xtp_t_' + cast(db_id() AS varchar(10)) + '_' +cast(object_id('dbo.T2_InMem') AS varchar(10)) + '.dll'
xtp klasöründekilere ek olarak File Group create ederken belirttiğimiz klasör içerisinde Checkpoint dosyaları oluşmakta. İki tür checkpoint dosyası mevcuttur:
Data File: Insert edilmiş satırlar ve önceki versiyonları.
Delta File: Data file içerisinde silinmiş olan satıların bilgisi. Bu dosya sayesinde silinen satırlar filtrelenerek tekrar memorye yüklenmez.
Birer çift olarak çalışan bu dosyaların hangilerinin aktif olarak kullanıldığını görmek için şu komutu kullanabilirsiniz.
select * from sys.dm_db_xtp_checkpoint_files
where is_active=1
Bu dosyaların çalışma mantığı anlaşılınca performansın nereden geldiği de ortaya çıkıyor.
DELETE komutu gönderdiğinizde gerçekten silme işlemi yapılmıyor. Sadece satır timestamp yardımıyla silindi olarak işaretleniyor. INSERT işlemi de direk memory üzerinde çalışan bir işlem. Bu esnada transaction log’da ya çok az kayıt tutuluyor veya tablo oluşturma yöntemine göre hiçbir kayıt tutulmuyor. UPDATE işlemi de zaten bir DELETE(eski kayıt) ve bir INSERT(yeni kayıt) işleminden oluşmaktadır.
Bu işlemler Natively Procedure içerisinde yapılırsa T-SQL kodunun C kodlarıyla ifade edilmesi safhası atlanmış olur ve dolayısıyla daha fazla performans elde edilmiş olur.
Memorydeki bilgilerin Data ve Delta dosyalarına yazılması işlemine Checkpoint deniyor. Zaman zaman bu dosyalar belli bir boşluk oranına ulaştığında ise otomatik olarak merge ediliyor. Kullanılmayan checkpoint dosyaları da birtakım şartlar oluştuğunda Garbage Collector mekanizması yardımıyla temizleniyor. Bu sistem kendi kendine işlemektedir. İstenirse sisteme müdahale edilebilir.
İşte bu çalışma mantığından dolayı OLTP işlemlerde 30 kata varan performans elde edebiliyoruz.
Blocklanmasını istemediğiniz, aynı anda birden fazla bağlantının açıldığı, kısa süreli transactionların yoğun olduğu OLTP işler için çalışan sistemlerde kullanılması tavsiye edilmektedir. Örnek olarak hisse senedi alım satımı, seyahat rezervasyonu ve sipariş işlemlerinin yapıldığı sistemlerde kullanılabilir. Geliştiriciler için ara işlemlerin yapıldığı örneğin ETL sürecinde tercih edilebilen temp tabloların yerine kullanılmasını da tavsiye olarak verebiliriz.
Bu teknolojinin performansından tam manası ile faydalanmak için artık daha fazla diretmeyip en azından canlı olmayan rapor ihtiyacı iş yükünü ayırmak gerekecek. Örneğin gün içinde yoğun bir şekilde gelen INSERT, UPDATE, DELETE talepleri In-Memory ile karşılanıp, gece vakti bu veriler SELECT işleminin yapılacağı raporlama amaçlı veri ambarlarına aktarılabilir.
Öncelikle In-Memory tablolar tutacağınız veri tabanında Memory Optimized Data File Group ve içerisinde File oluşturmanız gerekiyor.
ALTER DATABASE [testDB]
ADD FILEGROUP [InMemFileGroup] CONTAINS MEMORY_OPTIMIZED_DATA
GO
ALTER DATABASE [testDB]
ADD FILE (
NAME = N'InMemFile',
FILENAME = N'C:\Data\InMemFile'
) TO FILEGROUP [InMemFileGroup]
Hemen sonrasında Memory-Optimized tabloyu aşağıdaki şekilde oluşturabilirsiniz.
CREATE TABLE T2_InMem
(
Id int NOT NULL PRIMARY KEY
NONCLUSTERED HASH WITH (bucket_count=2000000),
Ad nvarchar(50),
Yas int NOT NULL,
Tarih datetime2 NOT NULL
INDEX IX_Yas NONCLUSTERED (Yas,Tarih)
)
WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA);
Tabloyu Memory-Optimized hale getiren en sondaki MEMORY_OPTIMIZED=ON ifadesidir. Hemen yanında belirtilenDURABILITY ifadesi ile verinin kalıcılığını örneğin server yeniden başlatılsa bile verinin memoryye tekrar yüklenip yüklenmeyeceğini belirtebiliyoruz. Buraya yazacağımız SCHEMA_AND_DATA ifadesi ile hem yapı hem de veri korunacaktır. Eğer bunun yerine SCHEMA_ONLY ifadesi kullanılırsa yapının kalıcılığı garanti altına alınır fakat veri kalıcı olmaz.
Yukarıdaki tablo örneğimizde sadece Memory-Optimized tablolarda kullanılabilecek iki index tanımladık. İçerisinde HASH ifadesi geçen Hash Index geçmeyen Range Index olarak isimlendiriliyor.
Yukarıdaki tanımdan bağımsız olarak Hash indexin yapısı şu şekildedir.
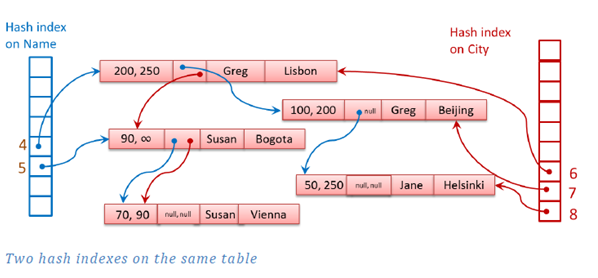
Index tanımlanırken bucket_count ile belirttiğimiz hücrelere veriler hash algoritmasından geçerek yerleşir.Bucket_count kolondaki unique satır sayısı olarak belirtilir. Belirtilen sayı otomatik olarak ikinin katlarından olacak şekilde bir sonraki sayıya çevrilir.
Insert ve Delete işlemleri (Update her iki işlemi kapsar) timestampler yardımıyla belirtilir. Satırlar pointerlar ile bir sonraki timestamp aralığını işaret eder. Yanında sonsuz işareti bulunan satırlar geçerli satırlardır. Hash indexler sorgu filtrelerinde eşitlikkullanıldığı durumlarda kendilerini gösterirler.
CTP2 versiyonu ile birlikte duyurulan bu index türü klasik B-Tree indexlerin değiştirilmiş(lock ve latch olmayacak şekilde) halidir. Yapısı Bw-Tree olarak geçmektedir. Bw-Tree hakkında daha fazla bilgi elde etmek için şu dosyayı inceleyebilirsiniz. http://research.microsoft.com/pubs/178758/bw-tree-icde2013-final.pdf
Bucket_Count belirtilmek istenmediği durumlarda ve aralık sorgulamalarının sıkça yapılacağı durumlarda bu index türü tercih edilmelidir.
Bu index türünde In-Memory mantığına uygun olarak eklenen satırların mantıksal adresleri Page Mapping Table isimli alanda sırayla tutulmaktadır. Diğer pageler de pointerlar yardımıyla bir sonraki pageleri işaret ederler. En son leaf seviyede satırların fiziksel adresleri tutulur. Index pageleri update edilmezler bunun yerine Page Mapping Table update edilir.
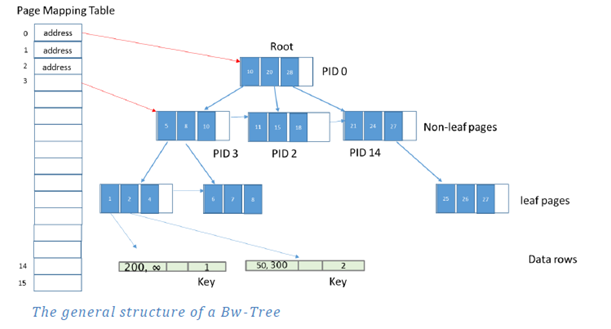
Bir takım şartlar yerine geldiğinde Garbage Collector mekanizması devreye girerek indexlerdeki geçerli olamayan satırları asenkron bir şekilde temizler.
Indexler disk üzerinde değildir. Index üzerindeki işlemler transaction logta tutulmazlar. İndex maintain işlem sırasında otomatik olarak gerçekleşir. Tüm indexler recovery sırasında rebuilt olurlar.
CPU ve Memory gücüne bağlı olarak farklı sonuçlar ile karşılaşabiliriz. Kendi ortamımda ve eğitimlerde yaptığım testlerde aşağı yukarı şu sonuçlarla karşılaştık.
INSERT
Aynı türdeki iki tabloya 500000(beş yüz bin) satır ekliyorum.
Disk-Based : 43 sn
Memory Optimized: 7 sn
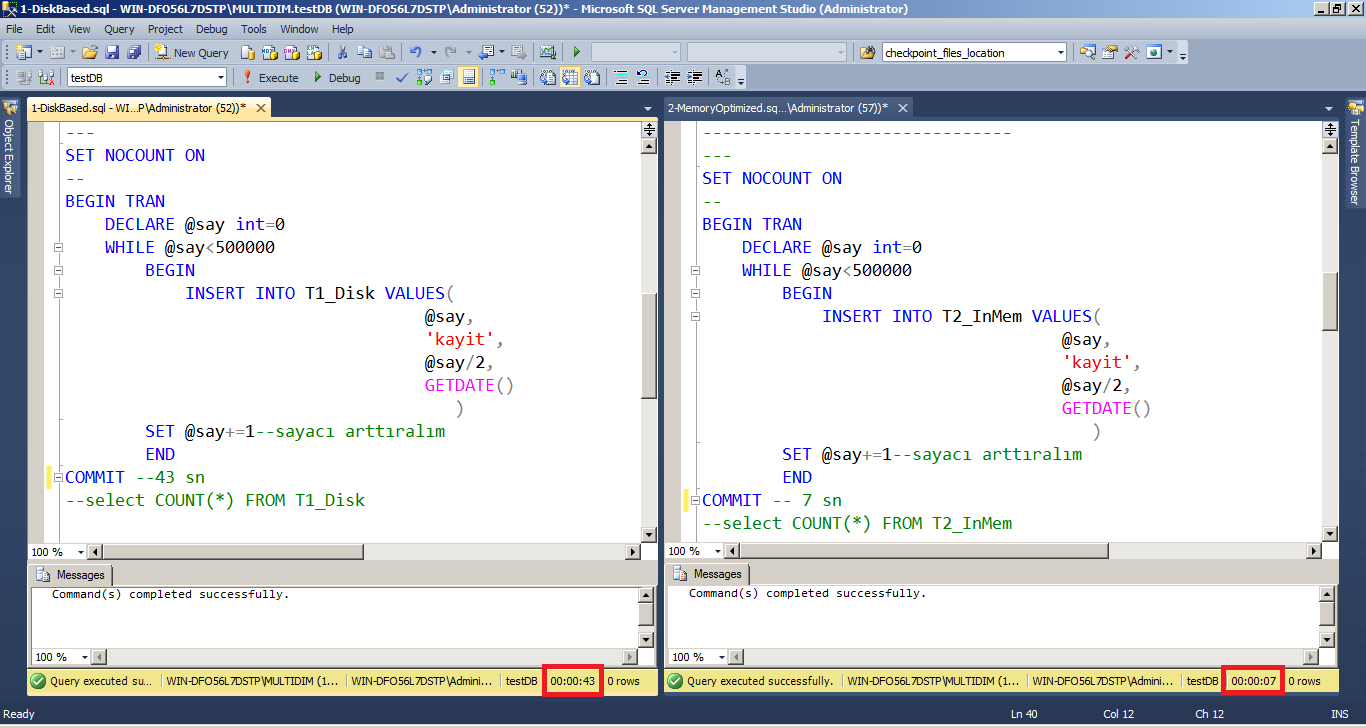
DELETE
Yüklü olan bu satırları silmek istediğimde ise:
Disk-Based : 12 sn
Memory Optimized: 2n
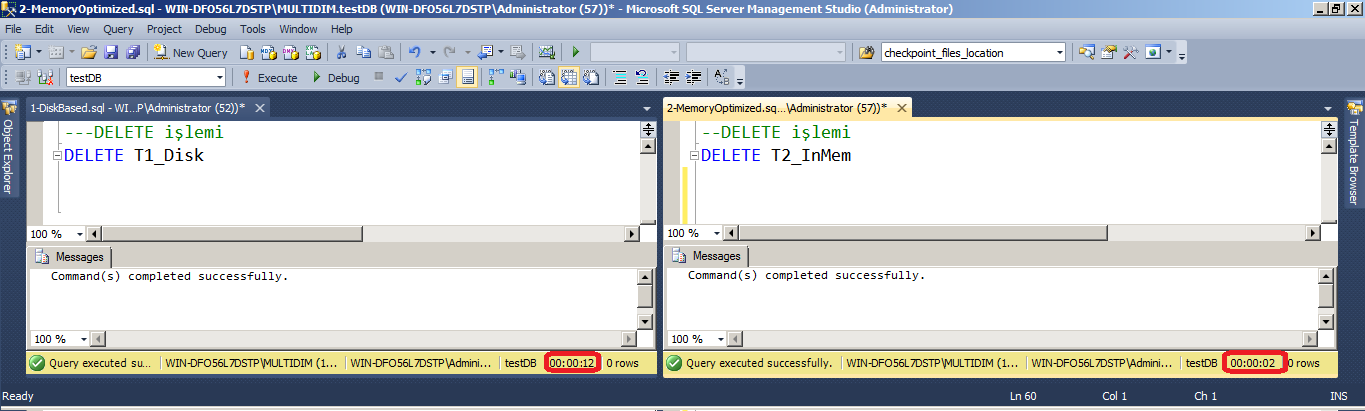
Eğer bu işlemleri Natively Procedure yardımıyla yaparsak fark çok daha ciddi olur.
Testimizi yapabilmek için öncelikle bir Natively Procedure oluşturalım. Procedure içerisinde aynı insert komutunu kullanıyor olacağım.
CREATE PROCEDURE dbo.usp_Native_Kayit
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS BEGIN ATOMIC WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
---
DECLARE @say int=0
WHILE @say<500000
BEGIN
INSERT INTO dbo.T2_InMem VALUES(
@say,
N'kayit',
@say/2,
GETDATE()
)
SET @say+=1--sayacı arttıralım
END
---
END
Buradaki NATIVE_COMPILATION ifadesi procedureün In-Memory kapsamında olduğunu gösteriyor. Bu tür precedürlerSCHEMABINDING ile işaretlenmesi zorunludur. Bu şekilde bağlı olduğu nesnelerin schemalarının değiştirilmesi engellenmiş olur. EXECUTE AS OWNER İfadesi ile de procedureün kimin yetkileri ile çalıştırılacağı belirtilmektedir.
Hemen sonrasındaki Transaction (varsa savepoint) başlatan BEGIN ATOMIC WITH ifadesinin içerisinde dilin, isolation seviyesinin ne olacağı gibi session ayarları belirtilir.
Procedure oluştuktan sonra aynı INSERT işlemini bu procedure ile test ettiğimizde milisaniyeler içerisinde 500000 kaydın eklenebildiğini görebiliyoruz.
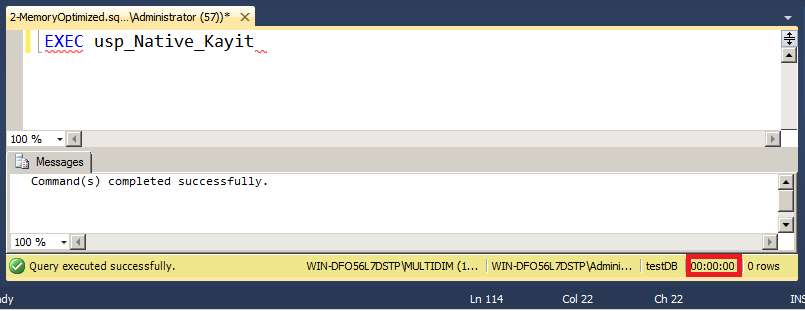
Daha ayrıntılı sonuçlar elde etmek için komutu çalıştırmadan önce SET STATISTICS TIME ON komutunu kullanabilirsiniz.
Kesinlikle hayır. Bu teknolojide birçok kısıt mevcut.
Kullanılamayan özelliklerden bazıları şunlar:
DML Trigger
XML ve CLR veri tipleri.
Varchar(max) gibi LOB tipleri.
IDENTITY
FOREIGN KEY
CHECK Constraint
ALTER TABLE
Sonradan Index oluşturma ve kaldırma(tablo yeniden create edilmeli)
TRUNCATE TABLE
Databaseler arası sorgulama
Linked Server
AlwaysOn Failover Cluster, AlwaysOn Availability Group ve Log Shipping tam olarak destekleniyor. Ancak In-Memory veri tabanın büyüklüğüne bağlı olarak recovery süresinin uzayacağını göz ardı etmemeliyiz. Çünkü failoverdan sonra tüm verinin memoryye yüklenmesi zaman alacaktır.
Ek olarak şöyle bir durum var; AlwaysOn Availability Group, secondary replicalardaki tabloları doldurmak için transaction log kayıtlarını transfer etmektedir. Non-Durable(SCHEMA_ONLY olarak işaretlenmiş) tablolardaki değişiklikler transaction loga yazılmadığı için bu tablolar secondary replicalarda boş görünecektir.
Her ne kadar High Availability kapsamında sayılmasa da bir tür veri transfer çözümü olan Transaction Replication ise belli kısıtlarla birlikte desteklenmektir. Daha fazla bilgi için şu linki inceleyebilirsiniz.
Evet mümkün. In-Memory kapsamındaki veri buffer pool’da değil doğrudan memoryde tutulmaktadır ve memory yönetimi de SQL Server sorumluluğundadır. Sonuç itibariyle Resources Governor sayesinde memory yönetimi yapılabilir.
Bunun için öncelikle istediğimiz özelliklerde bir pool oluşturmak gerekiyor. Biz bu örneğimizde memory kullanımını %50 olarak sınırladık.
CREATE RESOURCE POOL inMemPool
WITH (MAX_MEMORY_PERCENT=50);
ALTER RESOURCE GOVERNOR RECONFIGURE;
Sonrasında procedure yardımıyla TestDB isimli In-Memory veri tabanımızı pool ile ilişkilendiriyoruz(bind).
EXEC sp_xtp_bind_db_resource_pool 'TestDB','inMemPool';
Yapılan işlemin geçerli olması için veri tabanın yeniden başlatılması gerekli. Bunun için veri tabanını önce offline sonra tekrar online duruma çekiyoruz.
ALTER DATABASE TestDB SET OFFLINE;
ALTER DATABASE TestDB SET ONLINE;
Eğer In-Memory veri tabanının bu pool ile ilişiğini kesmek isterseniz. Aşağıdaki procedureü kullanarak unbind işlemini gerçekleştirebilirsiniz.
EXEC sp_xtp_unbind_db_resource_pool 'TestDB'
SQL Server 2014 ile birlikte monitörlemek için yeni DMVler geldi(içerisinde xtp ifadesi geçiyor.) ve mevcut catalog viewlerin bir kısmına yeni kolonlar eklendi. Ayrıca Veritabanı/Reports/Standart Reports/ Memory Usage By Memory Optimized Objects yolu ile aşağıdaki memory kullanım raporuna erişebilirsiniz.
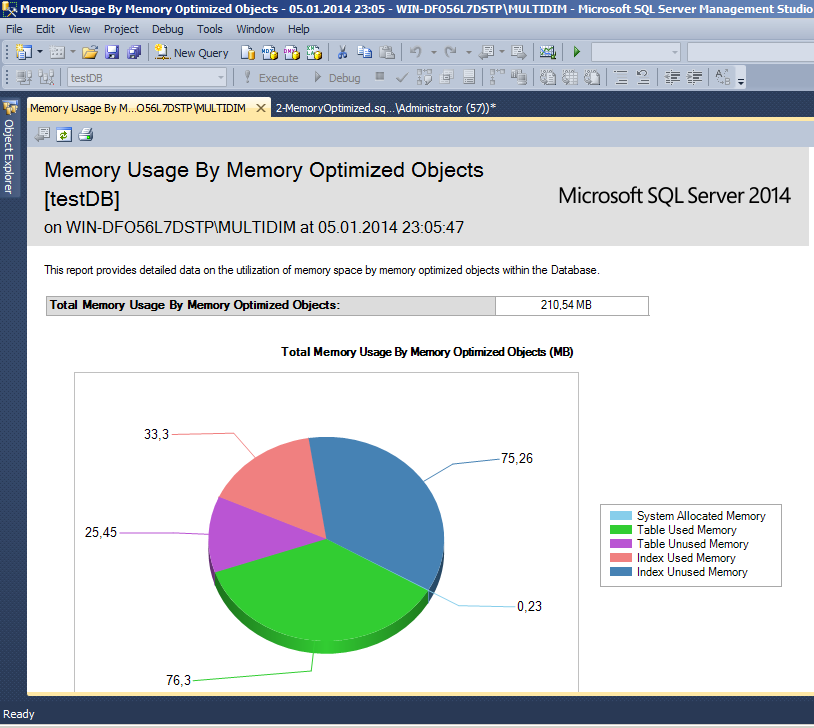
Şu sorgu yardımıyla da kullanılabilecek XEventleri listeleyebilirsiniz.
SELECT
p.name,
o.name,
o.description
FROM sys.dm_xe_objects o JOIN sys.dm_xe_packages p
ON o.package_guid=p.guid
WHERE p.name = 'XtpEngine';
Bu kapsamda kullanılabilecek performance counterlar ise şu sorgu ile listelenebilir:
SELECT
object_name,
counter_name
FROM sys.dm_os_performance_counters
WHERE object_name LIKE 'XTP%';
Bunun için SSMS’ya entegre Memory Optimization Advisor wizardı mevcut. Ancak öncesinde AMR (Analysis, Migration, Reporting) olarak isimlendirilen araç ile dönüştürmek isteyebileceğiniz tabloların hangileri olabileceği hakkında fikir edinebilirsiniz.
AMR aracı, SSMS’daki Object Explorer penceresinde Management klasörü altında görünen Data Collection özelliğini kullanılır.
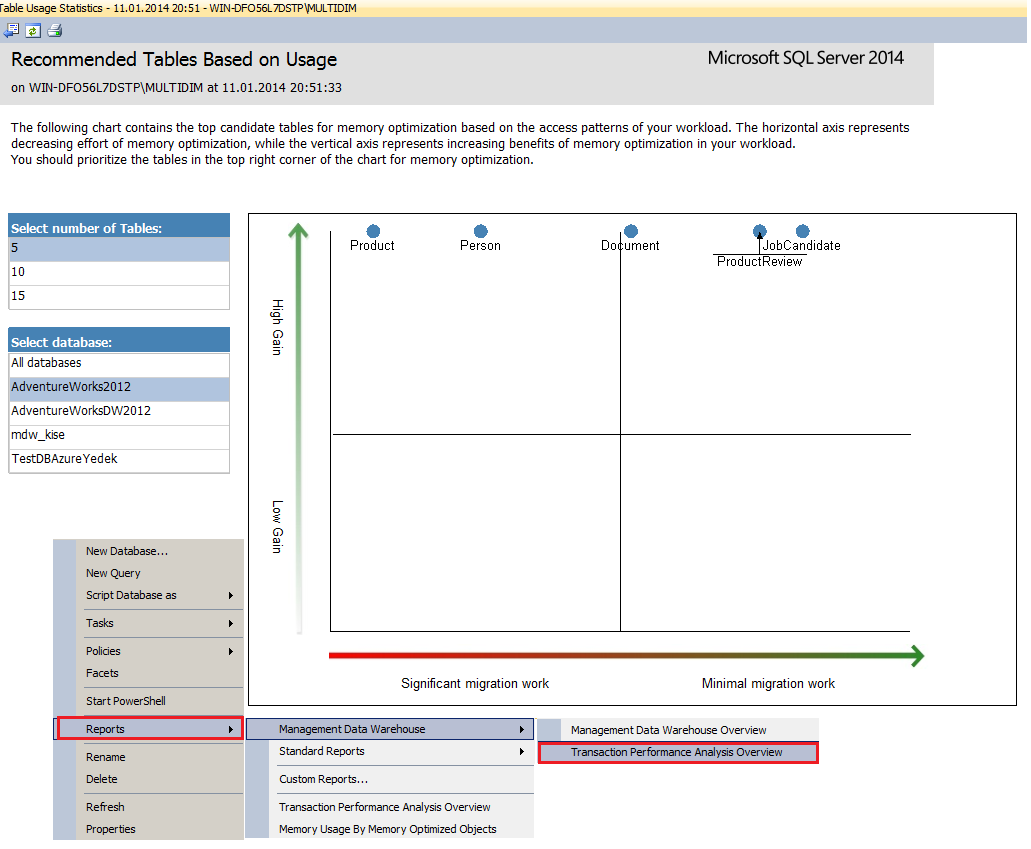
Data Collection sayesinde server hakkındaki bilgiler SQL Server Agent servisi yardımıyla belli aralıklarla belirtilen veri ambarına yüklenir. Buradan sistemin performansı ile ilgili çeşitli raporlar uzun zamandır elde edilebilir durumdaydı. Bu veri ambarı üzerinden erişilebilecek Transaction Performance Analysis Overview ve drill-through yaparak elde edilen diğer raporlar sayesinde transaction analizi yapabilir, ortaya çıkan quadrantlar yardımıyla minimum iş yükü ile maksimum fayda getirebilecek nesneleri görüntüleyebilirsiniz.
Eğer taşımak istediğiniz tabloları belirlediyseniz artık Memory Optimization Advisor wizardını kullanabilirsiniz.
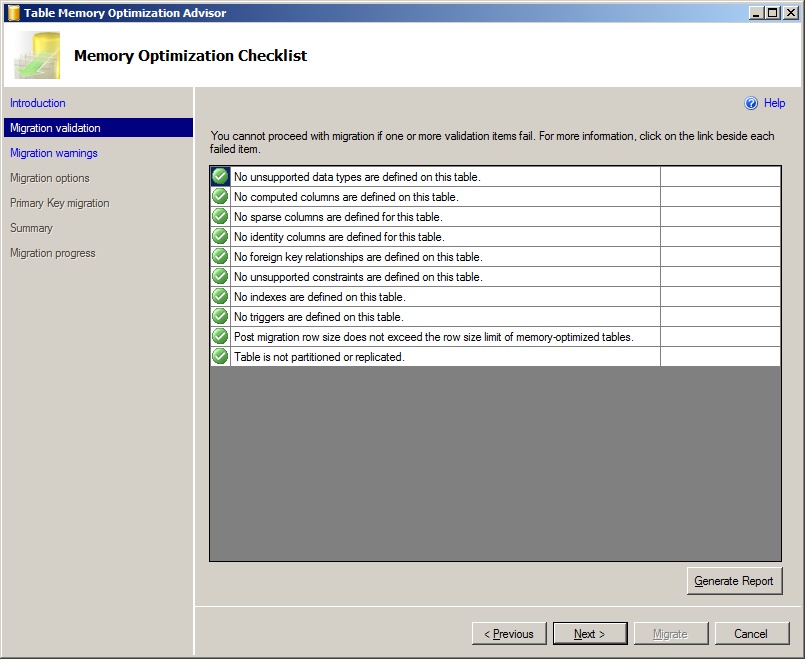
Taşımak istediğiniz tabloyu sağ tıklayıp Memory Optimization Advisor wizardını başlatıyoruz. İlk önce tablo üzerinde In-Memoryde desteklenmeyen özellikler kontrol ediliyor.
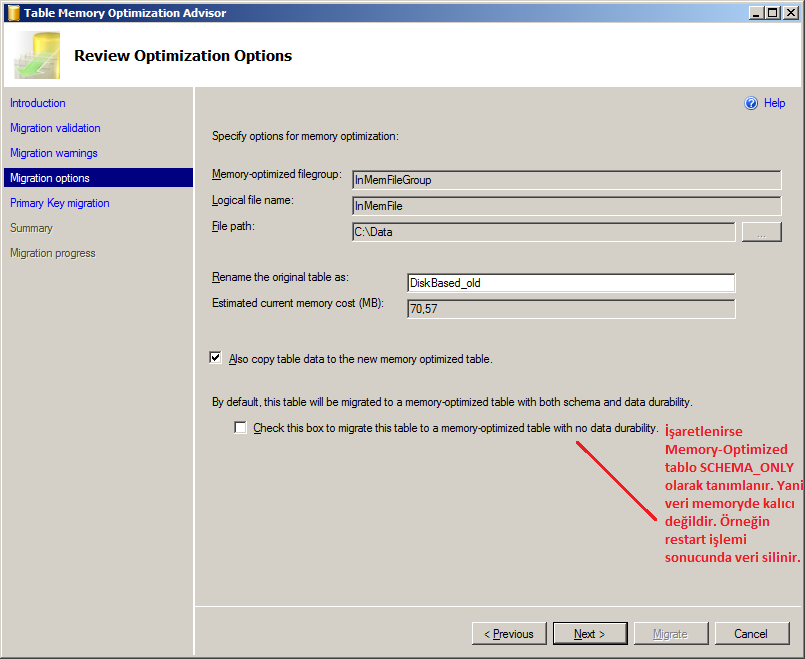
Diğer kullanılmayan özelliklerin uyarıları ile ilgili adımı da geçtiğimizde Memory-Optimized File Group ile birlikte içerisinde konumlanacak Logical File’ı ve Checkpoint dosyalarının tutulacağı klasörü belirtebiliyoruz. Yine burada taşıma işlemiyle birlikte Disk-Based tablonun adının ne olacağını ve verinin taşınıp taşınmayacağını ayarlayabiliriz. Bu adımdaki son seçeneği seçtiğimizde ise artık Memory-Optimized tablodaki veri Non-durable olacaktır.
Bir sonraki adımda Primary Key(Non-Durable seçilirse opsiyonel) ve index seçimi yapılarak Migrate butonu ile taşıma işlemi başlatılır.
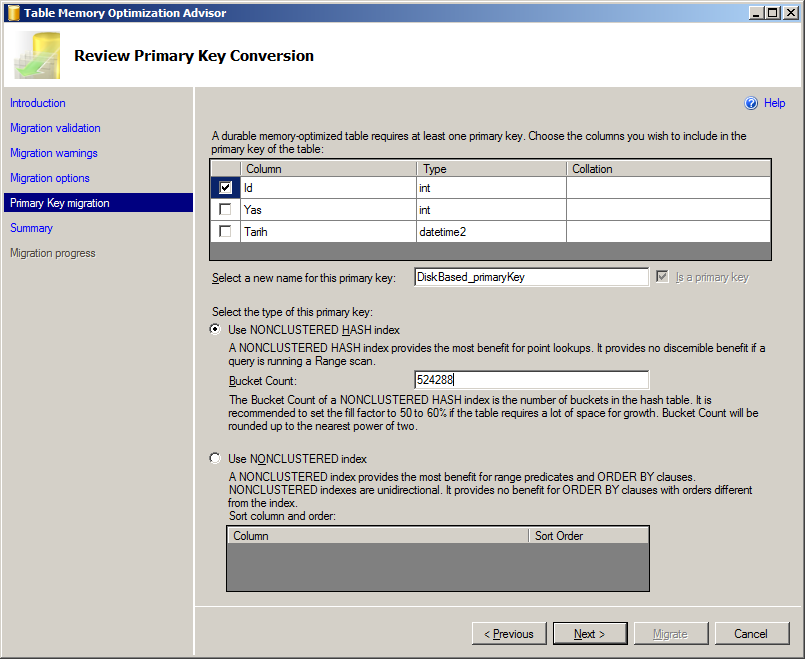
Natively-Compile Procedure üretmek için de benzer bir yöntem var ancak sadece template script elde edilmekte. Bu yöntemi testDB/Programability/Stored Procedure/New/ Natively Compiled Stored Procedure menüsünü kullanarak deneyebilirsiniz.
Bu araçlar yardımıyla gerekli kurulum sadece birkaç adımda tamamlanabilmektedir. Script veya ara yüz tercih size kalmış.
Baştan beri birlikte neler yaptığımızı özetlemek gerekirse;
In-Memory OLTP başlıklı çözümün alt yapısını, çalışma şeklini, karakteristiğini inceledik. OLTP işlemlerde ciddi manada performans elde edilebileceğini örnekledik. Kısıtlarını göz önünde bulundurarak mevcut sistemlere hangi şartlarda uygulanabileceğini konuştuk. Memory yönetimi ve entegre araçlarıyla kolayca kurulum – monitörleme yapılabildiğini gördük.
Artık sıra sizde! Sisteminizde hangi tabloların bu iş için uygun olabileceğini belirlemek ve yakın geleceğin trendi olan In-Memory hakkındaki gelişmeleri takip etmek isteyebilirsiniz.
In-Memory OLTP’yi birkaç cümle ile özetlemek gerekirse:
Lock ve Latch olmayan. ACID kurallarını destekleyen ve multi-version optimistic concurrency control prensibi ile transactionları yöneten. Verinin memoryde tutulduğu. Arka planda C ve FileStream nesnelerinin kullanıldığı mevcut Database Engine’e entegre yeni bir teknoloji. Bu teknoloji INSERT, UPDATE, DELETE performansını 30 kat arttırmak konusunda iddialı.
Abdullah KİSE
Veri Yönetimi ve İş Zekâsı Ekibi



